
The eCommerce industry is constantly evolving, and customer expectations are higher than ever. One of the biggest challenges retailers face is providing personalized, real-time assistance that matches the diverse needs of their customers. Static chatbots and FAQ pages often fail to bridge this gap, leading to lost sales and frustrated users.
As part of our team’s ongoing mission to solve classical eCommerce problems using cutting-edge AI/ML technologies, we set out to build a Virtual Shopping Assistant powered by Large Language Models (LLMs). This assistant was designed to understand natural language queries, provide personalized product recommendations, and handle common customer service tasks, all in real time.
Here’s how we approached this challenge step by step.
Problem Statement
Traditional eCommerce systems often fall short in these areas:
- Customer Query Understanding: Customers often ask questions in natural language, such as I need a gift for my mom under INR 500. Keyword-based search engines struggle to interpret such queries effectively.
- Personalized Recommendations: Static recommendation engines fail to account for real-time user preferences or contextual needs.
- Customer Support: Handling queries about returns, shipping policies, or product details often requires human intervention, which can lead to delays.
Our goal was to build an AI-powered assistant that could:
- Understand complex customer queries in natural language.
- Provide personalized recommendations based on user preferences.
- Handle FAQs and support queries autonomously.
Technical Implementation
Step 1: Selecting the Right LLM
We evaluated several LLMs based on their ability to understand complex queries and generate accurate responses:
- OpenAI GPT-4: Known for its state-of-the-art performance in natural language understanding and generation.
- LLaMA 2 by Meta: An open-source alternative that is highly customizable but requires domain-specific fine-tuning.
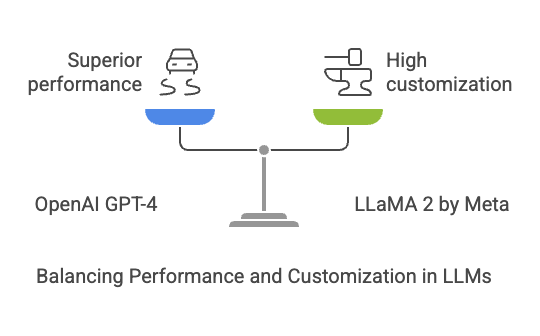
After initial testing, we chose GPT-4 for its out-of-the-box performance during prototyping. However, we also fine-tuned LLaMA 2 later for cost optimization and domain-specific improvements.
Step 2: Fine-Tuning the Model
While GPT-4 performed well on general queries, it lacked domain-specific knowledge about our eCommerce platform. To address this, we fine-tuned LLaMA 2 using historical customer interaction data from the retailer’s database.
Data Collection
We collected ~50K customer queries from past interactions, categorized into:
- Product Search (e.g., Find me a red gown for a wedding under INR 5000).
- Order Status (e.g., Where is my order?).
- Returns & Refunds (e.g., How do I return a product?).
Data Preprocessing
The data was cleaned and labeled into categories for supervised fine-tuning:
- Removed duplicates and irrelevant entries.
- Tokenized text using Hugging Face’s AutoTokeziner.
Fine-Tuning Workflow
Using Hugging Face’s transformers library, we fine-tuned LLaMA 2 with domain-specific data:
from transformers import AutoTokenizer, AutoModelForCausalLM
from transformers import Trainer, TrainingArguments
# Load base model
tokenizer = AutoTokenizer.from_pretrained("meta-llama/Llama-2")
model = AutoModelForCausalLM.from_pretrained("meta-llama/Llama-2")
# Define training arguments
training_args = TrainingArguments(
output_dir="./fine_tuned_model",
num_train_epochs=3,
per_device_train_batch_size=8,
learning_rate=5e-5,
)
# Fine-tune the model
trainer = Trainer(
model=model,
args=training_args,
train_dataset=fine_tuned_dataset,
)
trainer.train()Fine-tuning allowed us to tailor the model’s responses to our specific use case while reducing inference errors.
Step 3: Integrating with eCommerce APIs
To make the assistant functional within an eCommerce platform, we integrated it with Shopify’s API:
- Product Catalog: Fetch real-time product data like names, descriptions, prices, and inventory levels.
- Order Management: Retrieve order statuses for customer queries.
- Support Queries: Provide answers about returns and shipping policies by referencing pre-defined FAQs.
We used FastAPI to create a lightweight backend that connected the LLM with Shopify’s API:
from fastapi import FastAPI
import requests
app = FastAPI()
@app.post("/recommendations")
def get_recommendations(query: str):
response = query_llm(query)
products = fetch_products_from_shopify(response)
return {"products": products}This integration ensured seamless communication between the assistant and the eCommerce backend.
Step 4: Optimizing Performance
One of the key challenges was ensuring low-latency responses (<500ms) while querying both the LLM and external APIs. We addressed this by:
- Caching Frequent Queries: Using Redis to store responses for commonly asked questions (e.g., “What is your return policy?”).
- Retrieval-Augmented Generation (RAG): Implementing RAG pipelines with Pinecone to ground LLM outputs in factual product data.
Challenges Faced
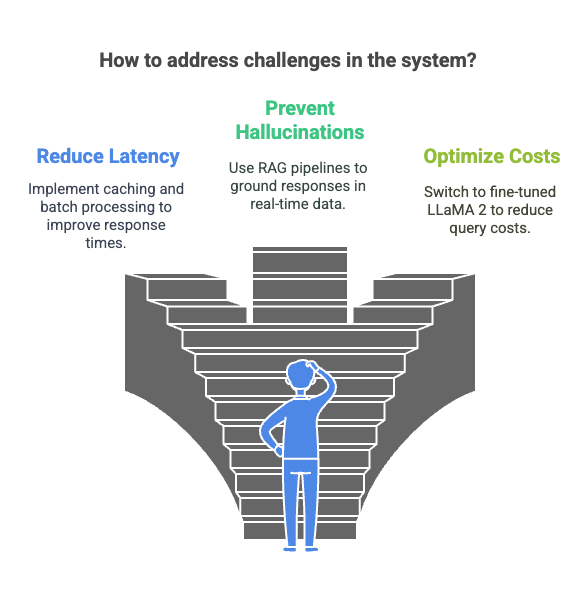
- Latency Issues : Initial response times were ~2 seconds due to API calls and LLM inference delays. By caching frequent queries and optimizing API calls with batch processing, we reduced latency to ~700ms.
- Hallucinations : The model occasionally suggested products that didn’t exist in the catalog (e.g., recommending “blue sneakers” when only “red sneakers” were available). Implementing RAG pipelines solved this issue by grounding responses in real-time product data.
- Cost Optimization : Using GPT-4 for every query was expensive during prototyping (~$0.03/query). Switching to fine-tuned LLaMA 2 reduced costs by ~60% without compromising accuracy.
Results Observed
After deploying the Virtual Shopping Assistant in a sandbox environment:
- Customer satisfaction scores increased by 25%, as users appreciated personalized recommendations and instant support.
- Cart abandonment rates decreased by 18% during A/B testing compared to static search engines.
- Query resolution time improved by 40%, thanks to caching and optimized API calls.
Key Learnings
- Fine-tuning domain-specific models significantly improves performance but requires high-quality labeled data.
- Retrieval-Augmented Generation (RAG) is essential for grounding LLM outputs in factual data.
- Cost optimization is critical for scaling AI solutions—open-source models like LLaMA 2 offer great flexibility when fine-tuned properly.
Next Steps
Building on Phase 1’s success, our team is now exploring:
- Multimodal capabilities (e.g., image-based search using vision-language models like CLIP).
- Expanding the assistant’s scope to handle dynamic pricing based on demand forecasting.
- Deploying self-healing mechanisms where the assistant can auto-debug errors in its responses.
Conclusion
Phase 1 of our experiment demonstrated how AI-powered assistants can transform customer engagement in eCommerce by providing personalized recommendations and instant query resolution. By leveraging LLMs like GPT-4 and fine-tuning open-source models like LLaMA 2, our team showcased its technical expertise in solving classical eCommerce problems efficiently.
Reach Out to Us
At DigiCraft Technovision Private Limited, we are passionate about leveraging AI/ML technologies to solve real-world problems in eCommerce and beyond. If you have any questions about this project or want to explore how AI can transform your business operations, feel free to reach out!
📧 Email us at [email protected]
🌐 Visit our website at https://digicraft.ai
Let’s collaborate and innovate together!


